샘플문항
(Hint: P(Z<-1.96)=0.025, P(Z<-1.645)=0.05, P(Z<-1.28)=0.10)
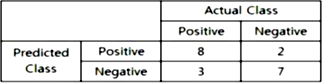

(점은 학습 데이터이고, 실선은 Regression Tree의 출력이다)
- 문항의 정답은 해당 회차의 시험 환경에서 산출된 결괏값을 기반으로 작성되었으며,
실기 문항은 패키지/라이브러리 버전에 따라 정답이 상이할 수 있습니다. - 사전에 신청한 실기툴 한 가지에 대해, '필요 패키지/라이브러리 목록'과 '툴가이드'가 주어집니다.
-
글로벌 유통 회사에서 매출액을 증대시킬 수 있는 마케팅 방법을 찾기 위하여,
채널별 반응과 매출금액과의 관계를 분석하고자 한다. -
01_ADS_sample_1.csv(구분자: comma(“,”), 169 Rows, 5 Columns, UTF-8 인코딩)
컬럼 정의 Type YEAR_MONTH 년월, YYYY-MMM 형태 (2018-Jan) String SOCIAL 일평균 SNS 조회수 Double TV 일평균 TV광고 시청자수 Double NEWSPAPER 일평균 신문기사 구독자수 Double SALES_AMT 매출금액 Double
- 피어슨(Pearson) 상관계수 값을 구하시오
- 상관계수는 절대값을 취하지 않은 상관계수 값 그대로, 소수점 넷째 자리에서 반올림하여 셋째 자리까지 기술하시오. (답안예시 : 0.123)

- 연도는 년월(YEAR_MONTH) 변수로부터 추출하며, 연도별 매출금액합계는 1월부터 12월까지의 매출 총액을 의미한다.
- 증감률(%)은 소수점 넷째 자리에서 반올림하여 셋째 자리까지 기술하시오. (답안예시 : 1.234)
단, 검정 시 세운 대립 가설(H₁)은 다음과 같다.
- 등분산 가정 하에서 검정을 수행한다.
- 2009년 매출금액(SALES_AMT) 12건과 2019년 매출금액(SALES_AMT) 12건에 대한 평균 검정으로, 해당 검정의 검정통계량은 자유도가 22인 t 분포를 따른다
- 유의 확률(P-value)값은 소수점 넷째 자리에서 반올림하여 셋째 자리까지 기술하시오. (답안예시 : 0.123)
툴별 가이드
| Brightics | 문제 지시 외 Default값 사용 |
|---|---|
| R | t.test() 함수의 var.equal=T 옵션 사용 문제 지시 외 Default 값 사용 |
| Python | from scipy import stats |
Associate(입문) 실기 샘플 풀이 (Brightics) 동영상 보기
X가 독립변수이며, 주어진 데이터의 개수는 10개이다.
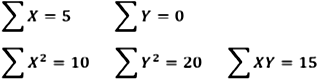
k 값 사이의 관계로 올바른 것은 무엇인가?
전체 조사일 중 기압이 높은 비율 = 12/20
비가 온 날 중 기압이 높은 비율 = 2/7
- 문항의 정답은 해당 회차의 시험 환경에서 산출된 결괏값을 기반으로 작성되었으며,
실기 문항은 패키지/라이브러리 버전에 따라 정답이 상이할 수 있습니다. - 사전에 신청한 실기툴 한 가지에 대해, '필요 패키지/라이브러리 목록'과 '툴가이드'가 주어집니다.
-
마케팅 전략을 수립하기 위해 신용 카드 고객을 대상으로
고객 세분화(Customer Segmentation) 및 예측 모델링을 수행하고자 한다. -
DS_Sample_1.csv (구분자: comma(“,”), 1,000 Rows, 18 Columns, UTF-8 인코딩)
컬럼 정의 Type CUST_ID 고객 ID Double BALANCE 연간 평균 잔고액 Double BALANCE_FR EQUENCY 연중 잔고액 갱신 개월 수 비율 (0~1 사이값) Double PURCHASES 구매 총액 Double ONEOFF_PURCHASES 일시불 구매 총액 Double INSTALLMENTS_PURCHASES 할부 구매 총액 Double CASH_ADVANCE 현금서비스 구매 총액 Double PURCHASES_FREQUENCY 연중 구매 개월 수 비율 (0~1 사이값) Double ONEOFF_PURCHASES_FREUQUENCY 연중 일시불 구매 개월 수 비율 (0~1 사이값) Double PURCHASES_INSTALLMENTS_FREQUENCY 연중 할부 구매 개월 수 비율 (0~1 사이값) Double CASH_ADVANCE_FREQUENCY 연중 현금서비스 구매 개월 수 비율 Double CASH_ADVANCE_TRX 현금 서비스 구매 횟수 Double PURCHASES_TRX 구매 횟수 Double CREDIT_LIMIT 신용카드 한도 Double PAYMENTS 지불 총액 Double MINIMUM_PAYMENTS 기한 내 최소 지불 금액 Double PRC_FULL_PAYMENT 연중 기한 내 전액 지불 개월 수 비율 (0~1 사이값) Double TENURE 신용카드 서비스 이용기간 Double 필요 패키지/라이브러리 목록
Brightics R dplyr, data.table, tidyr, cluster, tree Python import pandas as pd
import numpy as np
from sklearn.metrics import silhouette_samples, silhouette_score
from sklearn.cluster import KMeans
from sklearn.tree import DecisionTreeRegressor분석을 수행하기 전, 상기 데이터를 이용하여 아래의 전처리를 수행하시오.
단계 1 : ‘신용카드 한도(CREDIT_LIMIT)’와 ‘기한 내 최소 지불 금액(MINIMUM_PAYMENTS)’의 결측 값(Null)을 각 컬럼의 평균값으로 대체하시오. (배점 : 10점)
상기 전처리를 완료한 데이터셋(데이터셋명: card1)을 이용하여 다음 1~3번 문제에 답하시오.
‘신용 카드 서비스 이용기간(TENURE)’ 별로 ‘연간 평균 잔고액(BALANCE)’과 ‘신용카드 한도(CREDIT_LIMIT)’ 간 피어슨(Pearson) 상관 계수를 계산하고, 이 중 가장 큰 값을 구하시오.
단계 1: ‘고객 ID(CUST_ID)’를 제외한 모든 변수(17개)에 대해 Z-score 표준화(Standardization) 한다.
단계 2: 표준화된 변수들에 대해 K-means 군집 분석을 수행한다. 이 때, 군집 수는 2~5개 중 K-means Silhouette 를 통해 구한 최적의 K로 설정한다.
단계 3: 단계 2에서 도출한 각 군집 별로 ‘일시불 구매 총액(ONEOFF_PURCHASES)’의 평균을 계산한다.
툴별 가이드
| Brightics | Seed=1234 문제 지시 외 Default 값 사용 |
|---|---|
| R |
library(cluster) set.seed(12345) 표준화 : scale() 함수의 center=T, scale=T 옵션 사용 Silhouette : silhouette() 함수의 sil_width 평균값 기준 문제 지시 외 Default 값 사용 |
| Python |
from sklearn.metrics import silhouette_samples, silhouette_score from sklearn.cluster import KMeans random_state=1234 문제 지시 외 Default 값 사용 |
군집 별 ‘일시불 구매 총액(ONEOFF_PURCHASES)’의 평균 중 가장 큰 값을 구하시오.
단계 1: ‘고객 ID(CUST_ID)’가 4의 배수가 아닌 데이터를 Train Set으로, 4의 배수인 데이터를 Test Set으로 분할한다.
단계 2: Train Set으로 아래 조건에 따라 의사결정나무 회귀모델을 학습한다.
- 독립 변수(총 16개): ‘고객 ID(CUST_ID)’, ‘일시불 구매 총액(ONEOFF_PURCHASES)’을 제외한 모든 컬럼
- 종속 변수: ‘일시불 구매 총액(ONEOFF_PURCHASES)’
툴별 가이드
| Brightics | Seed=1234 문제 지시 외 Default 값 사용 |
|---|---|
| R | set.seed(1234) library(tree) Decision Tree Regression : tree() 함수 사용 문제 지시 외 Default 값 사용 |
| Python | from sklearn.tree import DecisionTreeRegressor random_state=1234 문제에서 지시한 것 외에는 Default 값 사용 |
단계 3: 생성된 모델을 Test Set에 적용하여 ‘일시불 구매 총액(ONEOFF_PURCHASES)’을 예측한다.
단계 3에서 얻은 예측 결과를 평가하기 위해, 아래 정의된 Measure B를 구하시오.
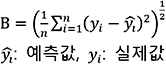
Advanced(중급) 실기 샘플 풀이 (Brightics) 동영상 보기